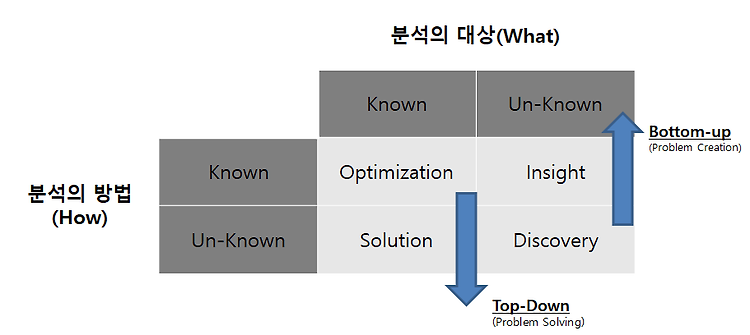
1. 분석과제 발굴 방법론 개요 하향식 접근법과 상향식 접근법 상향식 (바텀-업) 접근법의 대표적인 방법론: 프로토타입 모델 하향식 (탑-다운) 접근법의 대표적인 방법론: 폭포수 모델 최적의 의사결정은 두 접근방식의 상호 보완 관계 → 디자인 씽킹 2. 하향식 접근법 1) 문제 탐색 ① 비즈니스 모델 기반 문제 탐색 비즈니스 모델 캔버스를 활용한 과제 발굴 방법 5가지 영역 ② 분석 기회 발굴의 범위 확장 분석 기회 발굴의 범위 확장의 4가지 관점 - 거시적 관점의 메가 트렌드: STEEP (social, technological, economic, enviromental, political) - 경쟁자 확대 관점: 대체재, 경쟁자, 신규 진입자 - 시장의 니즈 탐색 관점: 고객, 채널, 영향자 - 역량..