1. 대용량 로그 데이터 수집
가. 로그(log)
- 로그(log)는 기업에서 발생하는 대표적인 비정형 데이터로, 과거에는 문제 상황 보존을 위해 사용됐고, 최근에는 마케팅/영업 전략 수립을 위한 사용자의 형태 분석 등에 사용된다.
- 용량이 방대하기 때문에 이를 분석하기 위해서는 고성능과 확장성을 가진 시스템이 필요하다.
- 로그 데이터 수집 시스템의 예 : 아파치 Flume-NG, 페이스북 Scribe, 아파치 Chukwa 등
나. 대용량 비정형 데이터 수집 시스템의 특징
- 초고속 수집 성능과 확장성
- 데이터 전송 보장 메커니즘
- 다양한 수집과 저장 플러그인
- 인터페이스 상속을 통한 애플리케이션 기능 확장
2. 대규모 분산 병렬 처리 (하둡)
- 하둡(Hadoop)은 대규모 분삭 병렬 처리의 업계 표준인 맵리듀스(MapReduce)시스템과 분산 파일시스템인(HDFS)를 핵심 구성요소로 가지는 플랫폼
- 자바 기반의 오픈 소스 프레임 워크
- 서버의 대수에 제한이 없음
- 비공유(Shared nothing) 분산 아키텍처 시스템: 서버를 추가하면 서버의 대수에 비례해 증가함 - 선형적인 성능
- HDFS에 저장되는 데이터는 3중복제로 되어 있어 고장감내성이 좋음
- 맵리듀스 작업 수행 중 특정 태스크에서 장애가 발생하면, 시스템이 자동으로 감지해 장애가 발생한 특정 태스크만 다른 서버에서 재실행 가능
- 하둡의 맵리듀스는 맵과 리듀스라는 2개의 함수만 구현하면서 동작하는 시스템
3. 하둡 에코시스템
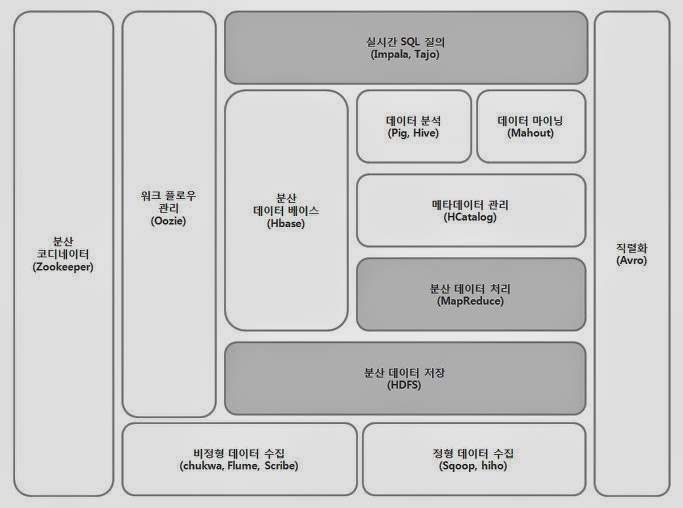

- 데이터 연동 솔루션 기술 - 스쿱(Sqoop): RDBMS와 NoSQL 연동이 가능 (Import와 Export 명령어를 통해)
- 대용량 SQL 질의 기술 - Hive: 대용량 데이터를 배치 처리하는데 최적화
- 실시간 SQL 질의 - SQL on 하둡: 아파치 드릴, 아파치 스팅거, 아파치 타조, 임팔라 등
반응형
'ADP(데이터분석 전문가) > 스터디노트' 카테고리의 다른 글
| [2과목] 분산 컴퓨팅 기술 (0) | 2021.02.09 |
|---|---|
| [2과목] 분산데이터 저장 기술 (0) | 2021.02.07 |
| [2과목] EAI(Enterprise Application Integration) (0) | 2021.02.02 |
| [2과목] CDC(Change Data Capture) (0) | 2021.02.02 |
| [2과목] 데이터 처리 프로세스 (0) | 2021.02.02 |