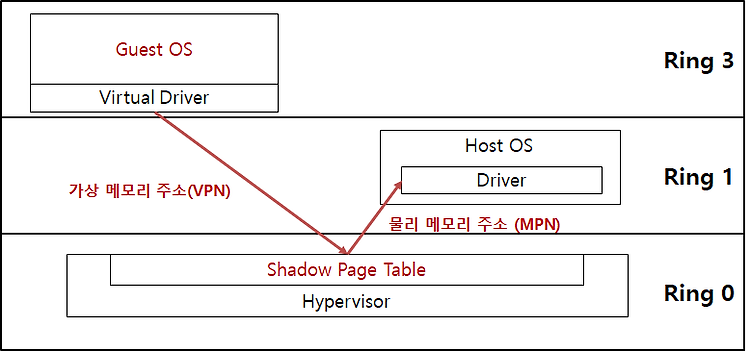
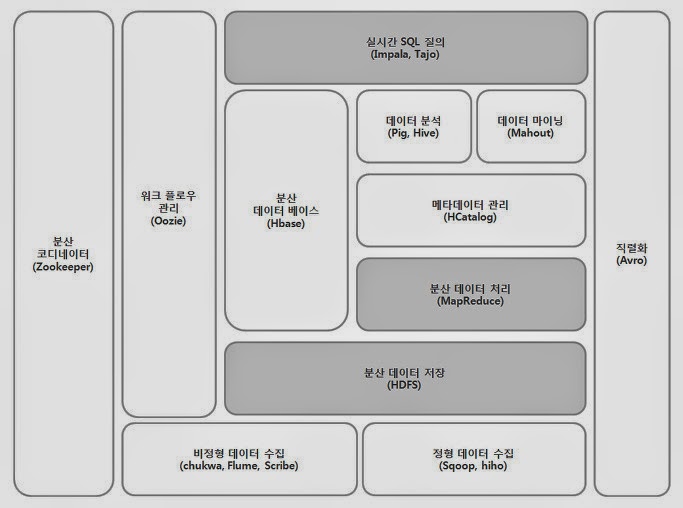
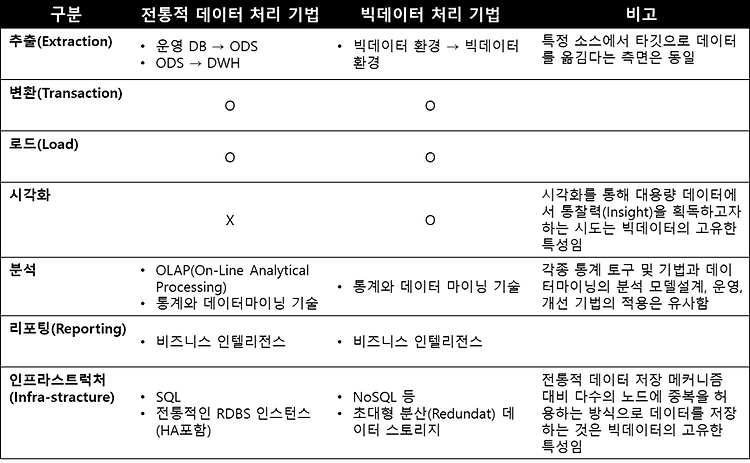
흔히 인공지능 = 딥러닝 인것처럼 착각하는 사람들이 많다. 나는 아직도 이분야에 비전문가들이 와서 얘기하는 것이 맘에 안든다.. 1. 인공지능 (Artificial Intelligence: AI) 인간의 학습 능력과 같은 기능을 수행하는 기계의 능력 인공지능(人工知能, 영어: artificial Intelligence, AI)은 인간의 학습능력, 추론능력, 지각능력, 논증능력, 자연언어의 이해능력 등을 인공적으로 구현한 컴퓨터 프로그램 또는 이를 포함한 컴퓨터 시스템 - 위키피디아 인공지능 이라는 말 뜻에는 어디에도 인공신경망 모형을 쓴다느니 파이썬으로 코딩을 한 프로그램이라는 말이 없다. 즉, 인공지능 이란 말은 학술적, 추상적인 용어일 뿐이다. 그렇기에 '인공지능'이라는 말을 창시한 존 매카시(Joh..