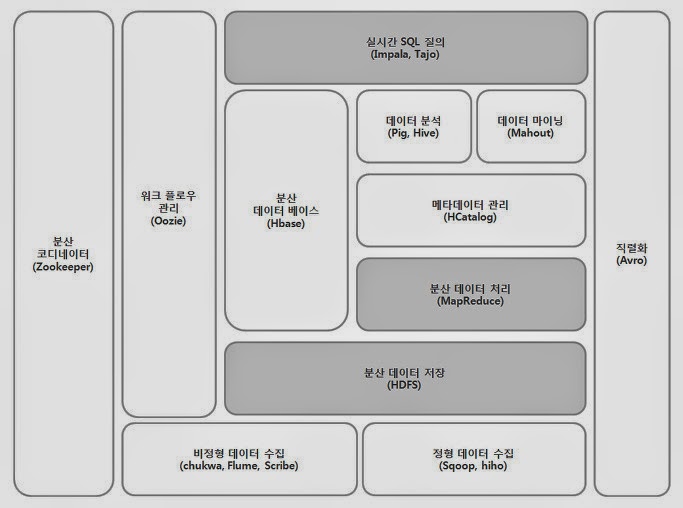
1. MapReduce 분산 병렬 컴퓨팅 Map Task 하나가 개의 블록(64MB) Map 함수는 어떤 key-value를 input으로 받아서 각 단어와 관련 발생 횟수를 출력 Reduce 함수는 특정 단어에 대해 생성된 모든 카운트를 합산 1) 구글 MapReduce - Map 함수: 다수의 새로운 key, value의 쌍으로 변환 (suffling과 group by 정렬) - Reduce 함수 2) 하둡 MapReduce ① 클라이언트에서 Job이라 불리는 하둡 작업을 실행 ② 프로그램 바이너리와 입출력 디렉터리와 같은 환경 정보들이 JobTracker에게 전송 ③ JobTracker는 다수의 Task로 쪼갠 후 큐에 저장 (Task는 맵퍼나 리듀서가 수행하는 단위 작업) MapReduce 단계 ..