1. 데이터 분석 도구의 현황
- 분석도구 비교
|
|
SAS |
SPSS |
R | Python |
|
프로그램 비용 |
유료, 고가 |
유료, 고가 |
오픈소스, 무료 |
오픈소스, 무료 |
|
설치용량 |
대용량 |
대용량 |
모듈화로 간단 |
모듈화로 간단 (배우기 쉬움) |
|
다양한 모듈 지원 및 비용 |
별도구매 |
별도구매 |
오픈소스 |
오픈소수 |
|
최신 알고리즘 및 기술반영 |
느림 |
다소 느림 |
매우 빠름 |
매우 빠름 (기계학습에 능숙) |
|
학습자료 입수의 편의성 |
유료 도서 위주 |
유료 도서 위주 |
공개 논문 및 자료 많음 |
공개 논문 및 자료 많음 |
|
질의를 위한 공개 커뮤니티 |
NA |
NA |
매우 활발 |
매우 활발 |
|
유지보수 |
쉽다 |
쉽다 |
어렵다 |
어렵다 |
2. 대화형 모드와 배치모드
- 대화형 모드 (interactive mode): 프롬프트에 코딩을 하여 결과를 바로 알 수 있음
- 배치모드 (batch mode): 프로그램 파일 형태(사용자와 인터렉션이 필요하지 않는 방식)로 프로세스 자동화할 떄 사용 → batch.R, .bat 실행파일
3. 벡터(vector) vs 리스트(list)
- 공통점: 위치로 인덱스, 이름 지정 가능
- 차이점: 벡터는 동일 자료형, 리스트는 여러 자료형
- 행렬(matrix): 벡터의 차원
- 어레이(array): 행렬의 다차원
4. R 코드
- 변수 삭제하기: rm
- 문자열 추출: substr("bigdata", 1, 4)
- 데이터 프레임: data.frame(벡터, 벡터)
- 구조 변경: as.list(벡터)
- 행결합: rbind(d1, d2)
- 열결합: cbind(d1, d2)
- 병합: mergen(df1, df2, by= "공통 열 이름)
- 데이터셋 조회: subset(df, select=변수, subset=변수>조건)
- 함수적용(결과를 벡터, 행렬): vec <- sapply(a, func)
- 함수적용(결과를 리스트): list <- lsapply(a, func)
- 함수적용(데이터프레임): dff <- apply(df, 1, sum)
(1이면 행, 2이면 열)
- 집단별 함수적용: tapply(vec,factor, func)
- 벡터, 리스트 함수 적용: mapply(factor, vec1, vec2, vec3)
- Reshape 패키지의 melt(), cast()

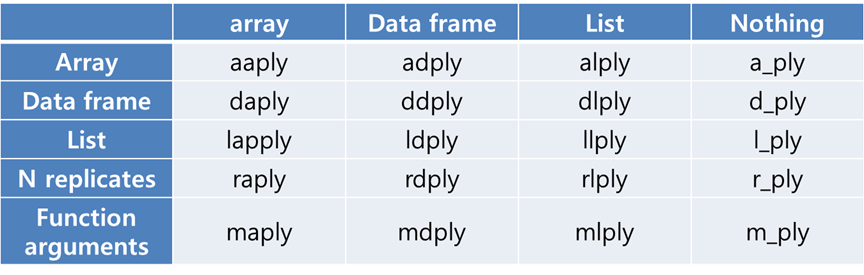
- plyr 패키지: apply함수에 기반한 입력과 출력데이터를 동시에 배열로 치환하여 처리하는 패키지
반응형
'ADP(데이터분석 전문가) > 스터디노트' 카테고리의 다른 글
| [4과목] 통계분석의 이해 (0) | 2021.02.28 |
|---|---|
| [4과목] 데이터 가공 (3) | 2021.02.25 |
| [4과목] 데이터 분석 개요 (0) | 2021.02.20 |
| [3과목] 분석 거버넌스 체계 수립 (0) | 2021.02.19 |
| [3과목] 마스터 플랜 수립 프레임 워크 (0) | 2021.02.18 |