1. MapReduce
- 분산 병렬 컴퓨팅
- Map Task 하나가 개의 블록(64MB)
- Map 함수는 어떤 key-value를 input으로 받아서 각 단어와 관련 발생 횟수를 출력
- Reduce 함수는 특정 단어에 대해 생성된 모든 카운트를 합산

1) 구글 MapReduce
- Map 함수: 다수의 새로운 key, value의 쌍으로 변환
(suffling과 group by 정렬)
- Reduce 함수

2) 하둡 MapReduce
① 클라이언트에서 Job이라 불리는 하둡 작업을 실행
② 프로그램 바이너리와 입출력 디렉터리와 같은 환경 정보들이 JobTracker에게 전송
③ JobTracker는 다수의 Task로 쪼갠 후 큐에 저장 (Task는 맵퍼나 리듀서가 수행하는 단위 작업)

- MapReduce 단계
스플릿(split)→ 맵(map)→컴바인(combine)→파티션(partition)→셔플(shuffle)→정렬(sort)→리듀스(reduce)
- 스플릿 단계에서 filesplit 하나당 맵 태스크(map task) 하나씩을 생성
- 맵 단계에서 map함수를 적용하여 key-value 쌍을 생성

2. 병렬 쿼리 시스템 <대용량 SQL 질의>
- MapReduce는 간단하지만 프로그래밍이 필요한 한계가 있어, 친숙한 쿼리 인터페이스를 가진 시스템
- 구글 Sawzall
- MapReduce를 추상화한 최초의 스크립트 형태 병렬 쿼리 언어
- 아파치 Pig
- Hadoop위에 작동하는 병렬 쿼리 언어 (야후에서 개발)
- 아파치 Hive
- Hadoop위에 작동하는 병렬 쿼리 언어 (페이스북에서 개발)
- 별도의 DBMS를 설정하지 않으면 Embedded Derby를 기본 데이터베이스로 사용

3. SQL on 하둡 <실시간 SQL 질의>
- 임팔라: 분석과 트랜잭션 처리를 모두 지원하는 것을 목표 (Java 대신 C++언어 기반)
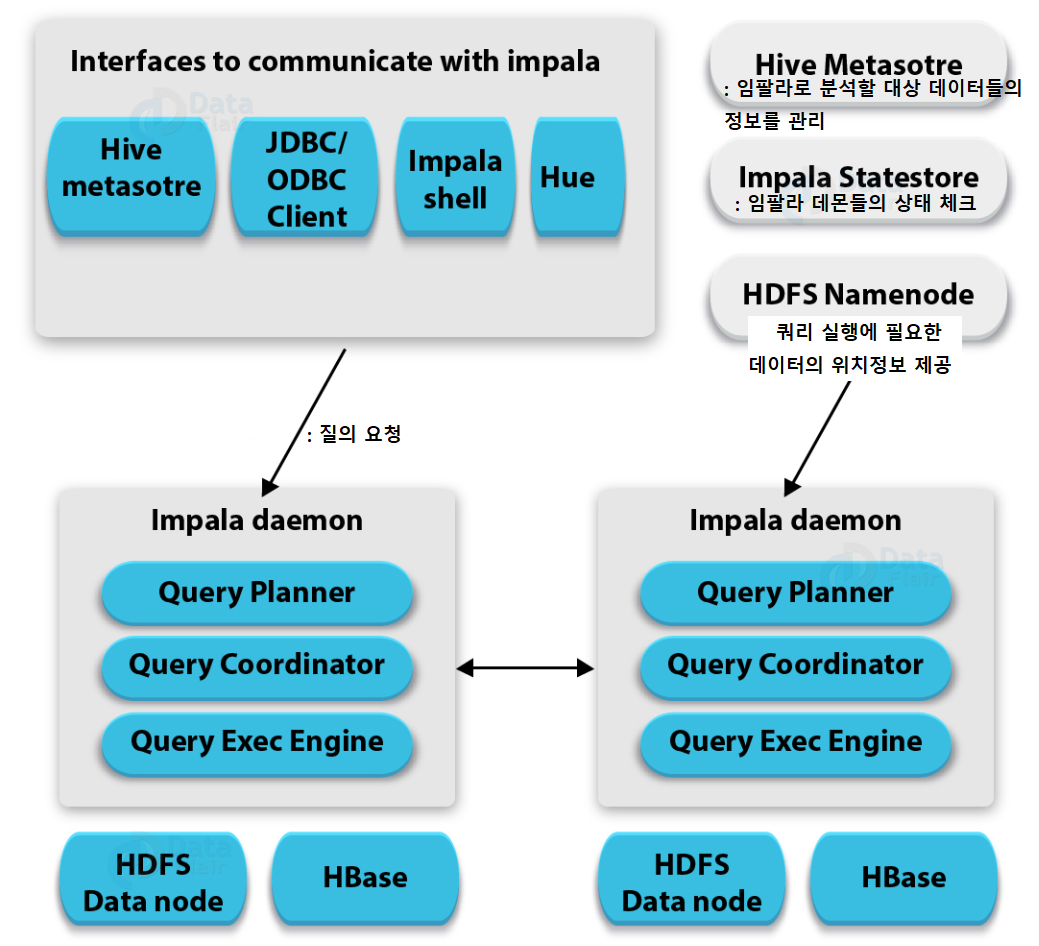
- 라운드 로빈방식: 여러 프로세스들이 순서대로 돌아가면서 처리되는 스케줄링 방식
반응형
'ADP(데이터분석 전문가) > 스터디노트' 카테고리의 다른 글
| [2과목] 클라우드 인프라 기술 - 2 (0) | 2021.02.13 |
|---|---|
| [2과목] 클라우드 인프라 기술 - 1 (0) | 2021.02.10 |
| [2과목] 분산데이터 저장 기술 (0) | 2021.02.07 |
| [2과목] 대용량의 비정형 데이터 처리 방법 (0) | 2021.02.02 |
| [2과목] EAI(Enterprise Application Integration) (0) | 2021.02.02 |