분산 데이터 저장 기술은 ① 분산 파일 시스템, ② 데이터베이스 클러스터, ③ NoSQL로 구분됨
1. 분산 파일 시스템
- 구글 파일 시스템(GFS, Google File System)
- 마스터, 청크서버, 청크
- 청크(chunk): 64MB의 고정된 파일 단위
- 쓰기 연산은 순차적
- 높은 처리율에 중점
- 클라이언트는 파일에 접근하기 위해 마스터로부터 해당 파일의 chunk가 저장된 chunk서버의 위치와 핸들을 먼저 받아온 뒤, 직접 청크서버에게 파일 데이터를 요청함

- 하둡 분산 파일 시스템(HDFS, Hadoop Distrubited File System)
- 네임노드 (=마스터), 데이터노드(=청크서버), 블록(=청크)
- 순차적 스트리밍 방식, 배치작업
- 높은 데이터 처리량에 중점



- 보조 네임노드: HDFS 상태를 모니터링 하며 주기적으로 네임 노드의 파일 시스템 이미지를 스냅샷해 생성 (= 세컨더리 네임노드)
- 러스터(Lustre)
- 클러스터 파일 시스템(Cluster File Systems Inc.)에서 개발한 객체 기반 클러스터 파일 시스템
- 메타데이터 서버(MDS), 객체저장 서버(OSS)

- OSS는 복수의 디스크 장치에 분산 저장시키는 '스트라이핑 방식'으로 분산 저장
- 라이트백 캐쉬: 클라이언트에서 메타데이터 변경에 대한 갱신 레코드를 생성하고 나중에 메타데이터 서버로 저장
- 메타데이터와 파일 데이터에 대한 동시성 제어를 위해 별도의 잠금을 사용해야 함 (intent 기반 잠근 프로토콜)
2. 데이터베이스 클러스터
- 데이터베이스 클러스터는 하나의 데이터베이스를 여러 개의 서버상에 구축하는 것을 의미
- 성능과 가용성의 향상을 위해 데이터베이스 차원의 파티셔닝(=클러스티링)을 이용
- 병렬처리: 파티션 사이의 병렬 처리를 통한 빠른 데이터 검색 및 처리 성능 얻음
- 고가용성: 특정 파티션에서 장애가 발생하더라도 서비스가 중단되지 않음
- 성능향상: 성능의 선형적인 증가 효과
1) 무공유 디스크
- 각 인스턴스나 노드가 완전이 분리된 데이터의 서브 집합으로 구성
- 대부분의 데이터 베이스 클러스터가 무공유 (예외: Oracle RAC)
- 장점: 노드 확장에 제한이 없다
- 단점: 각 노드에 장애가 발생할 경우를 대비해 별도의 Fault-tolerance를 구성해야 한다

2) 공유 디스크
- 각 인스턴스나 노드가 모든 데이터에 접근 가능 (Oracle RAC)
- 데이터 공유하려면 SAN(storage area network)와 같은 네트워크가 구성되어야 함
- 장점: 높은 수준의 Fault-tolerance를 제공한다
- 단점: 클러스터가 커지면 디스크 영역에서 병목현상이 발생한다

(예제)
- Oracle RAC
- 공유 DB 클러스터
- 클러스터의 모든 노드는 데이터베이스의 모든 테이블에 동등하게 액서스하며, 특정 노드가 데이터를 소유하는 개념이 없음
- 장점: 가용성(fault-tolerance), 확장성, 비용절감
- 도입 비용 때문에 화장성이 중요한 데이터보다는 고가용성을 요구하는 데이터에 많이 사용됨

- IBM DB2 ICE(Integrated Cluster Environment)
- 무공유 DB 클러스터
- MS SQL Server
- 연합(Federated) DB 클러스터 (=무공유)

- My SQL
- 무공유 DB 클러스터
- 데이터 노드는 최대 48개, SQL노드는 최대 255로 제한

3. NoSQL
- 비관계형(non-relational) DBMS (SQL 계열 쿼리 언어를 사용 가능, join 연산은 지원하지 않음)
- Key와 value 형태로 자료를 저장
- 데이터의 구조에 따라: Key-value모델, Document 모델(JSON, XML), Graph 모델, Column 모델로 구분
- 대부분 오픈소스
1) 구글 빅데이터
- 공유 DB 클러스터
2) HBase
- 하둡 분산파일 시스템(HDFS) 기반 NoSQL
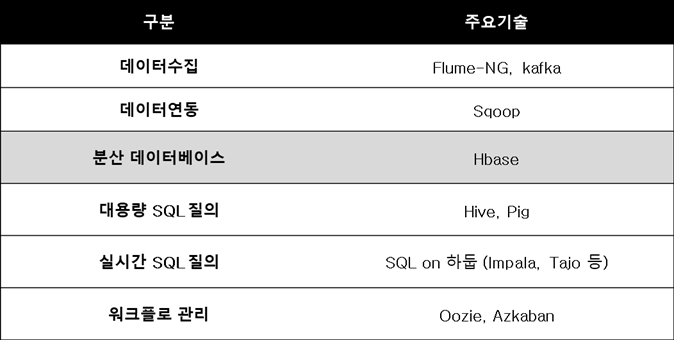
3) 아마존 Simple DB
- Domain, Item, Attribute, Value로 구성
- 도메인(=테이블 of RDB), 아이템(=레코드 of RDB), 어트리뷰트(=칼럼 of RDBM)


4) MS SSDS(SQL Server Data Service)
- 컨테이너, 엔티티로 구성
'ADP(데이터분석 전문가) > 스터디노트' 카테고리의 다른 글
| [2과목] 클라우드 인프라 기술 - 1 (0) | 2021.02.10 |
|---|---|
| [2과목] 분산 컴퓨팅 기술 (0) | 2021.02.09 |
| [2과목] 대용량의 비정형 데이터 처리 방법 (0) | 2021.02.02 |
| [2과목] EAI(Enterprise Application Integration) (0) | 2021.02.02 |
| [2과목] CDC(Change Data Capture) (0) | 2021.02.02 |