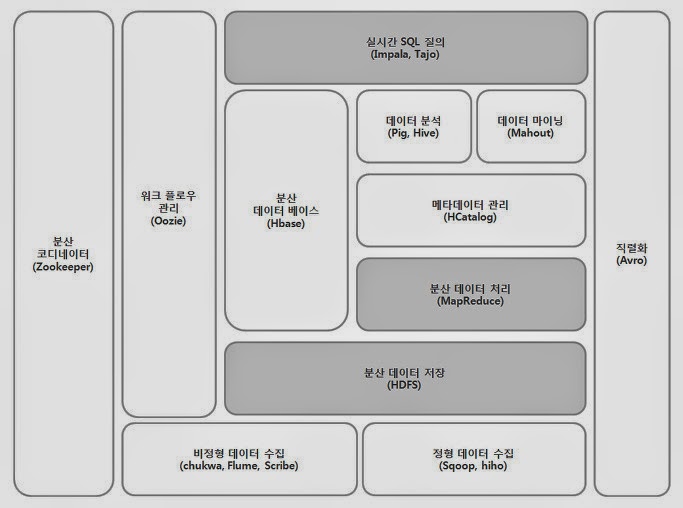
분산 데이터 저장 기술은 ① 분산 파일 시스템, ② 데이터베이스 클러스터, ③ NoSQL로 구분됨 1. 분산 파일 시스템구글 파일 시스템(GFS, Google File System) - 마스터, 청크서버, 청크 - 청크(chunk): 64MB의 고정된 파일 단위 - 쓰기 연산은 순차적 - 높은 처리율에 중점 - 클라이언트는 파일에 접근하기 위해 마스터로부터 해당 파일의 chunk가 저장된 chunk서버의 위치와 핸들을 먼저 받아온 뒤, 직접 청크서버에게 파일 데이터를 요청함 하둡 분산 파일 시스템(HDFS, Hadoop Distrubited File System) - 네임노드 (=마스터), 데이터노드(=청크서버), 블록(=청크) - 순차적 스트리밍 방식, 배치작업 - 높은 데이터 처리량에 중점 - 보조 ..